
English version (Version Française disponible sur makina corpus). estimated read time: 10min
Why?
Have you ever wondered why you cannot post any HTML on Facebook? It seems so easy on a lot of websites to submit content containing a small HTML subset, why doesn't Facebook allow it?
Or maybe you knew that it was possible in Facebook Notes, before April 2014. You had a little rich text editor where you could type in some HTML tags (both in wysiwyg and raw mode). But you cannot do that anymore. Now you are forced to use the wysiwyg mode and even using the API you will see that the very small part of HTML you can use will always be very very clean. Very few nested levels, very strict opening/closing policy for tags, no attributes, etc.
Well, in this article I'll try to explain why. I'll show you how, by simply playing with bad HTML syntax on a very small subset of HTML, it is easy for contributed HTML to evade the box and write everywhere on the page.
This earned me a 1500 USD facebook bounty (and a Github T-shirt). So, yes, it's very simple but it's still very annoying and real.
I like to look at very simple things and HTML box evasion is something very very simple. So simple that most people would not even see why it is a problem.
So, before reading, keep in mind that this is about HTML contributions and HTML injection, this is not about XSS or SQL injection. The problem here is:
- Can you let the user contribute content formatted with a small subset of HTML?
- Can you ensure the contributed content will stay in the box, in the dedicated layout subset.
This impacts every markup language that is rendered to HTML (like partial HTML, of course, but also markdown, reStructuredText, etc.).
So what?
Implicit HTML and the browser fixing your errors
When you feed a browser with some HTML, the browser is very kind and will try to fix a big number of errors that could be present in the page.
This behavior was a very important part of the web's success. If browsers made a White-Page-Of-Death for every HTML syntax error, the web would be really smaller.
This is cool for the end user.
This is cool for the web developer.
This is bad in terms of security.
One of the way browsers will fix HTML is by adding closing tags when the page clearly forgot to close some tags.
So this:
<!-- initial -->
<div class="foo">
<ul>
<li>foo
<li>bar
</ul>
</div>Is automatically rewritten with closing </LI>:
<!-- rendered -->
<div class="foo">
<ul>
<li>foo</LI>
<li>bar</LI>
</ul>
</div>But let's look at something nastier, we have an opening <DIV> inside the <LI>:
<!-- initial -->
<div class="foo">
<ul>
<li>foo
<div class="second">
test
</li>
<li>bar<li>
</ul>
</div>The browser will add the closing DIV:
<!-- rendered -->
<div class="foo">
<ul>
<li>foo
<div class="second">
test
</DIV> <!-- implicit HTML -->
</li>
<li>bar<li>
</ul>
</div>Chances are that a server side output filter, filtering HTML contributions would have detected this HTML as invalid, if you count opening and closing tags you can detect that a closing tag is missing.
So our bad contributor will instead write this:
<!-- initial -->
<div class="foo">
<ul>
<li>foo<div class="second"><div class="third">test</li>
<li>bar<li>
</ul>
</div> <!-- end third -->
</div> <!-- end second -->
</div>And if you count the number of closing and opening tags, or if you try to cleanup this with some regexp (are you crazy?), chances are that this will look good.
And now the browser result:
<!-- rendered -->
<div class="foo">
<ul>
<li>foo
<div class="second">
<div class="third">test
</DIV> <!-- implicit HTML - end third-->
</DIV> <!-- implicit HTML - end second -->
</li>
<li>bar<li>
</ul>
</div> <!-- end third? no, end foo -->
</div> <!-- end second? no end foo's parent if any -->
</div> <!-- end foo's parent's parent if any -->Two </DIV> are impliclty added by the browser, because you cannot close
the <LI> without closing the <DIV> inside. And now, on the final page, you have
2 extras closing divs !
Ok, too many closing divs, and then?
If the contributor can enter <div> and </div>, and if you count the number
of closing and opening divs to assume the HTML is correct, you are wrong.
The HTML is correct only if the order of the opening and closing tags is correct, if some tags are closed before some others it may break the layout (it depends of the tags).
For the contibutors, this means writing outside of the controlled zone (the
user-comment box for example) and adding content, with the subset of HTML that
they are allowed to use, on other parts of the page, maybe playing with <table>
and <br/> to fake content on some parts of your layout that other users will
trust more than a spam comment box (see last examples at the end of this text).
Demo
Below are some iframes that use the implicit DIV closing trick to write one
simple line of text on the main div, instead of writing it 3 nested DIV
deeper.
An interesting thing to do is opening these iframes in a new window and looking at the source. Here is what you'll see if you view the source of the first iframe:
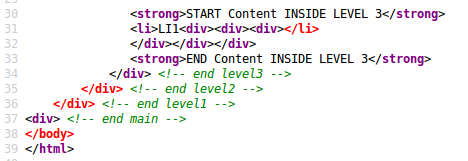
We can see that something wrong was detected and highlighted in red.
Inspecting the DOM we see how the browser automatcially closes the divs:
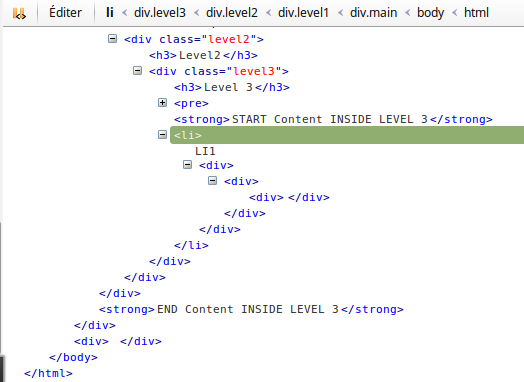
In these examples:
- the goal is to write something in red, in the main div
- somes tests should fail (using
<P>or<TD><TR>we do not break the divs as would most inline tags like<span>,<strong>,<sub>, etc.)
| direct link | direct link |
| direct link | direct link |
| direct link | direct link |
| direct link | direct link |
| direct link | direct link |
| direct link | direct link |
| direct link | direct link |
| direct link | direct link |
| direct link |
H1, H2, H3, PRE, LI
These are the tags I prefer because chances are that they are in the list of allowed tags for contributors.
Will it break <section> or <article>?
Yes.
First, if you allow <section> or <article> in allowed contributors tags, it
will obviously allow the contributor to close such tags, so this would be a very
bad move.
More generaly, if you use one <DIV> on your layout, closing this tag will also
close any <section> or <article> embedded inside.
Let's see this in action in a more complex layout:
Here is a new iframe with a full layout, you can see a div around the article.
And here is this layout after a bad comment closing the comment and main divs (the real aside section and footers are far in the bottom):
What if direct HTML is not allowed?
If the only way to contribute is Markdown, reStructuredText or other wiki-like syntaxes, you cannot directly insert bad HTML, in theory.
Well, for Markdown it depends of the flavor. By default, you can include raw HTML in Markdown, unless this feature is removed.
Anyway, with a language generating HTML the game is to find strange syntax in this language which will generate bad HTML.
Be careful, preview modes are usually made with syntax parsers written in JavaScript. These parsers are usually less robust than the real final generators. So a bad syntax in a preview mode means almost nothing.
I wont give you specific syntax error examples, it depends on the engine, you'll have to research on your own.
Protections
If you want to allow contributions, here are some thoughts:
- Why not simply allowing unformatted text?
- Why allowing
<div>? If you use<div>in your layout you could in fact prevent any contributions from using this HTML tag. - More generally do not allow tags used for your layout structure (like article or section)
- Check your CMS if you CMS provides HTML syntax cleanup (Drupal does, for example)
- Avoid regexps to cleanup (filter) contributed HTML, prefer DOM-based tools when they are available. These tools will analyze text input, build a dom tree, then generate HTML output from the tree, so tags will always be in the right order, and can even be filtered for attributes and id cleanup.
- That said, regexp-based filters might also work and perform the same filtering task, here is for example a very good drupal7 module, wysiwyg_filter


