
English version (Version Française disponible sur makina corpus). estimated read time: 10-15min
Generating massive amounts of data can be useful to test queries, indexes and complex treatments on more realistics volumes, to get useful approximations of production response times.
In this article we'll study some generate_series() usages allowing us to feed all types of tables.
The starting point is that we have two tables to feed (contact and company), with some constraints on these tables:
- a foreign key contraint, linking a
contactto onecompany - some constraints on column sizes (like for last name and first name)
- some specific constraints (CHECK) on dates (like a
contacthas some first and last interactions dates, and these dates have some constraints between each other, and cannot be in the future, etc.)
The other point is that we need to work on several tens of thousands of rows. For example to apply a functionnal process that need to be applied in production later and control the speed of this process. Or simply to test that our indexation plan is right.
Some tools exists, able to generate content. In the Django world, for example, you could use Factory Boy, or others. But here we'll show how to generate this same type of data in a quite simple manne, using SQL directly, in a very very fast way (fast enough to be added in a functionnal test setUp).
We first need a realistic model. With a company table, a contact table, some
index, and two or three lines of examples.
You can download an example basic_schema.sql script containing all these elements (direct download.
And we can also use SQLFiddle to visualize this structure online. But my advice is to create a test database and to run this SQL inside, it will be easier to test the complex queries in your own database.
Simple data generation
Let's use generate_series to generate some data :
-- tall numbers between 1 and 100 (step 1 by default)
SELECT generate_series(1,100);
-- all dates between 2010/05/10 and now,
-- with a step of 78 days, 15 hours and 10 minutes
SELECT * FROM generate_series('2010-10-05 00:00'::timestamp,
CURRENT_TIMESTAMP,
'8 days 15 hours 12min');
As we can see this function is quite powerful (SQLFidlle1 SQLFidlle2).
But our goal is to push this usage further.
Generating names from syllables
Let's start with this query which generates a lot of company names, we'll use that to feed the company table:
SELECT(
SELECT concat_ws(' ',name_first, name_last) as generated
FROM (
SELECT string_agg(x,'')
FROM (
select start_arr[ 1 + ( (random() 25)::int) % 16 ]
FROM
(
select '{CO,GE,FOR,SO,CO,GIM,SE,CO,GE,CA,FRA,GEC,GE,GA,FRO,GIP}'::text[] as start_arr
) syllarr,
-- need 3 syllabes, and force generator interpretation with the '0' (else 3 same syllabes)
generate_series(1, 3 + (generator0))
) AS comp3syl(x)
) AS comp_name_1st(name_first),
(
SELECT x[ 1 + ( (random() 25)::int) % 14 ]
FROM (
select '{Ltd,& Co,SARL,SA,Gmbh,United,Brothers,& Sons,International,Ext,Worldwide,Global,2000,3000}'::text[]
) AS z2(x)
) AS comp_name_last(name_last)
)
FROM generate_series(1,10000) as generator
As we can see on SQL Fiddle this somewhat strange query works and generates 10,000 company names, from 3 syllables and a final word (like "SOCOGEC 2000" or "COGEFOR Worldwide"). The query does not use any table, there's not even a model for this in SQL Fiddle.
In this query we can find some calls to RANDOM() allowing choices variations on syllables, the % 14 and % 16 are importants, they use the array effective size to choose randomly one the record in the array.
The most complex part of the request is the + (generator*0), reusing the identifier generated in generate_series,
multiplied by 0 (so doing nothing with it). Without this call the subquery would be optimized
and not a correlated one, and only on syllables combination would be generated. We would have 10,000 rows, with 10,000 identifiers, but the same company name for each line.
Once we have a good SELECT we just have to INSERT the result in the table, using an insert query of this form:
INSERT INTO matable(field1, field2)
SELECT ..... -- (here the select we just found) ....
ON CONFLICT DO NOTHING;
The ON CONFLICT part is ot available before PostgreSQL 9.5, it can be used to
ignore the unique key errors. On an older PostgreSQL you'll have to generate
a select without key errors (using disticnt for example), here with this
DO NOTHING I won't have any duplicate problem, they'll get rejected silently.
On our starting schema we add in SQL Fiddle the generation of some companies and we can see that we effectively loose one third of the companies as they were duplicates and were not inserted in the database.
More complex, again
We have companies.
Now we'll try to get a SELECT query with all the necessary columns for a contact insertion.
Using the same template as the company names we can quite easily generate last and first names. HERE, for example, I generate namesSQLFiddle. Note that if I remove the + (generator*0), we generate the same name for each line.
We can generate some fake company identifiers (a random int between 1 and 6300 for example) and find back this company to use the comapny name on the email address. Email that need to be complete the last and first name (without accents).
I can choose randomly a status on the contact status ENUM choices.
But we'll also need dates, Creation datetime, update datetime, and some interaction dates with these contacts.
For this task I will start by building a pseudo table with dates. I want to be able, for on contact, to choose one date in this tables and use it as a creation date. I will then have some other dates columns in this same table, where the dates are after the first one (some weeks after for a first date, and some more time for a second one).
By choosing randomly in this pseudo table I will be able to generate some profiles of contact creation dates and actions dates made on the contact.
I will use UNION queries in the dates collection to get different spannings, I want
a big number of dates on the last year, some others on the last 5 yers, and less on the last 10 years.
And of course i need these dates in a random order, but with an increment that I can use to match these dates as if it were an identifier.
THe source code of this sub group of 1083 lines each giving 3 dates is here and we can see it in action with SQLFidlle
rownum | base_date | date_up_to_7_days | date_up_to_3_months
--------+-------------------------------+-------------------------------+-------------------------------
1 | 2016-12-12 11:49:32.811583+01 | 2016-12-15 22:20:32.811583+01 | 2017-06-27 18:34:32.811583+02
2 | 2017-02-24 06:21:32.811583+01 | 2017-03-01 07:36:32.811583+01 | 2017-06-27 18:34:32.811583+02
3 | 2012-06-28 08:40:32.811583+02 | 2012-07-02 15:06:32.811583+02 | 2014-02-22 07:16:32.811583+01
4 | 2007-12-05 17:55:32.811583+01 | 2007-12-10 17:35:32.811583+01 | 2008-07-19 06:27:32.811583+02
5 | 2014-01-09 18:48:32.811583+01 | 2014-01-10 22:10:32.811583+01 | 2014-10-25 19:48:32.811583+02
6 | 2007-08-23 01:56:32.811583+02 | 2007-08-28 17:25:32.811583+02 | 2007-12-20 02:12:32.811583+01
7 | 2017-01-01 00:54:32.811583+01 | 2017-01-05 06:28:32.811583+01 | 2017-06-27 18:34:32.811583+02
8 | 2014-05-16 11:14:32.811583+02 | 2014-05-16 21:10:32.811583+02 | 2016-03-24 09:57:32.811583+01
This sort of data group can be used in my request like a table by using the keyword WITH:
WITH dates1083 AS (
... -- here the big dates select ...
)
SELECT * FROM
tbl1
INNER JOIN dates1083 ON tbl1.foo_id = dates1083.id
This avoids creating a temporary table, this table will only be used in the current query.
This query, with all the dynamic columns, all reusing a base generate_serie, will be quite big.
In a simplified version, where the big generators are replaced by [ ... comments blocs .. ] we'll get :
WITH dates1083 as (
[ .. Here the whole 1083 *3 columns pseudo table generation ... ]
)
INSERT INTO contact( con_id, con_active, con_firstname, con_lastname, con_mail, date_create, con_date_first_interaction, con_date_last_interaction, date_alter, con_status, comp_id ) SELECT id, con_active, CASE WHEN show_first_name THEN name_first ELSE NULL END as con_first_name, CASE WHEN show_last_name THEN name_last ELSE NULL END as con_last_name, -- con_mail concat_ws('@',co [ ... Here string manipulations, with column from company, name and first name ... ] ) as mail, -- date_create dates1083.base_date as date_create, -- con_date_first_interaction CASE WHEN (has_1st_interact=true) THEN dates1083.date_up_to_7_days ELSE NULL END as date_1st_interact, -- con_date_last_interaction CASE WHEN (has_2nd_interact=true AND has_1st_interact=true) THEN dates1083.date_up_to_3_months WHEN (has_2nd_interact=false AND has_1st_interact=true) THEN dates1083.date_up_to_7_days ELSE NULL END as date_2nd_interact, -- date_alter CASE WHEN (has_2nd_interact=true AND has_1st_interact=true) THEN dates1083.date_up_to_3_months WHEN (has_1st_interact=true) THEN dates1083.date_up_to_7_days ELSE dates1083.base_date END as date_alter, -- con_status con_status, -- company link main_sub.comp_id FROM ( -- name_first SELECT( [ .. Here first name generator ... ] ), -- name_last ( [ .. Here last name generator ... ] ), -- con_status ( [ .. Here status enum choice generator ... ] ), -- comp_id (used for joining company table, adding comp_name on email ( select (random() 10000)::int + (generator0) as comp_id ), -- base_date_num (used for joining dates1083 pseudo-table, and computing others dates from that ( select (random() 1083)::int + (generator0) as base_date_num ), -- con_active, something like 10% of false (inactive) ( select ((random() 10 + (generator0)) > 1)::boolean as con_active ), -- has_1st interaction something like 95% ( select ((random() 100 + (generator0)) > 5)::boolean as has_1st_interact ), -- has_2nd interaction something like 65% ( select ((random() 100 + (generator0)) > 35)::boolean as has_2nd_interact ), -- let's hide some non required fields sometimes -- hiding 5 % of last_names ( select ((random() 100 + (generator0)) > 5)::boolean as show_last_name ), -- hiding 5 % of first_names ( select ((random() 100 + (generator0)) > 5)::boolean as show_first_name ), -- id generator as id FROM generate_series(1,100) as generator ) main_sub INNER JOIN company ON company.comp_id = main_sub.comp_id INNER JOIN dates1083 ON dates1083.rownum = main_sub.base_date_num -- ignore conflicts of ids, but not any checks constraint failure (on dates for example) ON CONFLICT DO NOTHING;
Here is the full and commented version, without the INSERT part.
There's a lot of elements inside, my advice is to copy that in a pgadmin SQL session and to play with the various columns.
You have siome booleans generated on subqueries, allowing choices adjustemnts with CASE on the top queries,
to get more various profils, to insert some NULL sometimes on some non required columns, etc.
We can of course see it in SQL Fiddle where the model is already present, as we need the company table to get the right email column.
id | con_active | con_first_name | con_last_name | mail | date_create | date_1st_interact | date_2nd_interact | date_alter | con_status | comp_id
-----+------------+----------------+--------------------+----------------------------------------------------+-------------------------------+-------------------------------+-------------------------------+-------------------------------+------------+---------
1 | t | Coaïco | Takalaerjac | coaico.takalaerjac@cocaco-global.com | 2017-06-16 10:41:28.631596+02 | 2017-06-21 04:01:28.631596+02 | 2017-06-27 18:39:28.631596+02 | 2017-06-27 18:39:28.631596+02 | commercial | 4091
2 | t | Nnn | Otoerkingchen | nnn.otoerkingchen@sefrafor-international.com | 2016-03-12 04:25:28.631596+01 | 2016-03-15 07:34:28.631596+01 | 2016-10-22 05:57:28.631596+02 | 2016-10-22 05:57:28.631596+02 | external | 6055
3 | t | Cosyso | Steinroytakavur | cosyso.steinroytakavur@gecgipfor-global.com | 2016-12-16 10:35:28.631596+01 | 2016-12-18 18:11:28.631596+01 | 2016-12-18 18:11:28.631596+01 | 2016-12-18 18:11:28.631596+01 | production | 651
4 | t | Michavir | Ersteinotovur | michavir.ersteinotovur@gefroca-international.com | 2012-10-29 12:27:28.631596+01 | 2012-11-03 10:41:28.631596+01 | 2013-06-19 11:21:28.631596+02 | 2013-06-19 11:21:28.631596+02 | external | 2731
6 | t | Ennathche | Latakamcata | ennathche.latakamcata@gecforgim-united.com | 2016-12-15 12:29:28.631596+01 | 2016-12-19 11:12:28.631596+01 | 2017-06-27 18:39:28.631596+02 | 2017-06-27 18:39:28.631596+02 | external | 8740
8 | f | | Durjactakao' | borob.durjactakao-@forfrafor-gmbh.com | 2014-01-13 16:36:28.631596+01 | 2014-01-17 19:08:28.631596+01 | 2014-01-17 19:08:28.631596+01 | 2014-01-17 19:08:28.631596+01 | external | 1902
9 | t | Jamibo | Jacsteinlason | jamibo.jacsteinlason@gimgipgim-international.com | 2011-11-30 08:29:28.631596+01 | | | 2011-11-30 08:29:28.631596+01 | support | 3024
10 | t | Nathhnnath | Vurfürsteinking | nathhnnath.vurfursteinking@sosegip-sons.com | 2014-08-29 00:10:28.631596+02 | 2014-09-04 05:25:28.631596+02 | 2014-09-04 05:25:28.631596+02 | 2014-09-04 05:25:28.631596+02 | support | 6006
13 | t | Chepeche | Kleindurotoking | chepeche.kleindurotoking@sogegec-global.com | 2011-07-25 03:06:28.631596+02 | 2011-07-28 14:17:28.631596+02 | 2013-08-08 10:32:28.631596+02 | 2013-08-08 10:32:28.631596+02 | direction | 477
(...)
We'll then need to insert those lines into the contact table. As we could see before on the above pseudo-query.
After the WITH section we have a SELECT query, the INSERT INTO contact part has to be paste just before this select.
At the end we have this insert query,
where we also add the ON CONFLICT DO NOTHING;.
Then I can insert 1,000, 10,000 or 100,000 contacts by simply altering the digits in the last generate_series.
For SQL Fiddle the model definition and these queries reached the size limit (8000) so UI had to remove some indexes and some formating and comments, but it works !
We can also list some contacts.
Or start to work on some complex query from an application. Since the goal is normally to find the right indexes.
Why, by the way?
Generating datas based on a realistic physiognomy of data and on large assemblies will help us validate an indexation scheme, and optimize explains.
The query shown in this previous Fidlle and also available directly here is quite awful to optimize, with WINDOW usage, some subselects, etc.
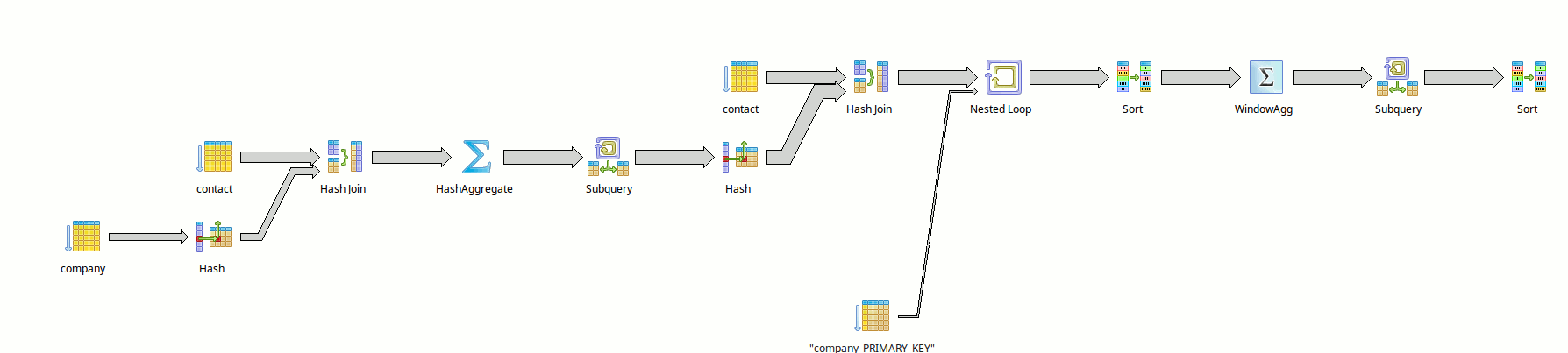
On the other hand, depending on the presence or absence of certain indexes (like the dates partial indexes), we can obtain some very different explain schemes:
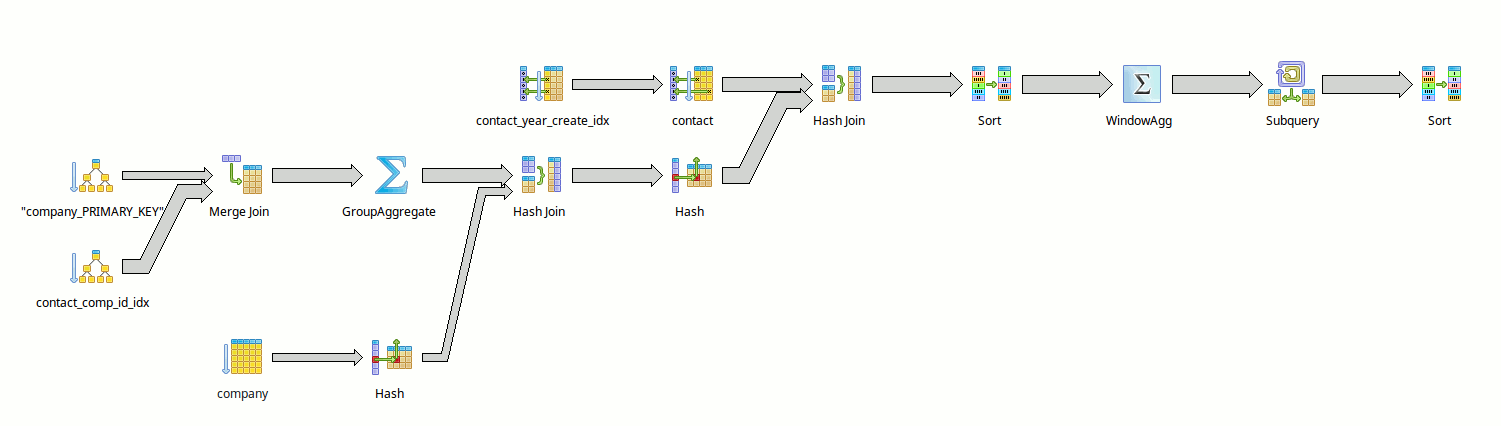
But that's another story.
Bonus
Of course variations on the examples can be made. Here is a link to a hoity-toity french names generator.


